


发布日期:2025-03-02 13:26 点击次数:95
自打 DeepSeek 全球爆火以后, AI 圈里齐跟按了快进键一样,齐好顿加快。
别的不说,光这一周就有马斯克的 Grok 3 ,Anthropic的 Claude 3.7 Sonnet ,阿里的通义 QwQ-Max-Preview ,腾讯的 Turbo S ,月之暗面的 Kimi-1.6-IoI-High ,谷歌的 Gemini Code Assist 啥的一大堆东西,还有个 DeepSeek 开源周,简直是仙之东谈主兮列如麻。

而就在昨晚,回回被拿出来鞭尸,每次齐自称在憋大的的 OpenAI 终于憋出来了,掏出了 GPT 系列的船新版块, GPT-4.5 。
按奥特曼的说法,这回这个 GPT-4.5 是一种不同类型的智能,其中有着他从未感受过的奇妙之处,这将是第一个让你嗅觉在和一个有想想的东谈主话语的模子。

不外,自打两个月前哥们连着十几天,次次更阑两点追他们败兴发布会,说真话奥特曼有点伤了哥们的心了。
是以咱其实对这个 GPT-4.5 也没报啥盼望,以至发布会上奥特曼东谈主齐没来,说是回家带孩子去了,对,就他跟他老公俩男的生的阿谁娃。
归正举座看下来,我只可说 GPT-4.5 这波算是 “ 唐唐 ” 亮相了。
这倒不是哥们尬黑,其他网友们对这玩意无数亦然这个宗旨,外网上以至有个 GPT-4.5 是不是垃圾的磋商,因为就连红脖子们也不看好 GPT ,齐投票给了马斯克的 xAI 。

是以这玩意到底若何个拉法呢,不卖关子,咱平直说论断,那等于 GPT-4.5 性能不可,况兼价高。
通常是昨晚发布,但他跟 su7u 属于是悉数反着来。
先说性能吧,在一个 OpenAI 官方给出的基准测试里, GPT-4.5 在科学,数学,编码才略上齐比不上自家前年发的 o3-mini ,基准测试也只比 4o 好 5% 。

也等于说, GPT-4.5 在 AIME 和 GPQA 等难题的学术基准测试上,比较自家 o3-mini 齐是不太够的,更别说跟 DeepSeek-R1 和 Claude 3.7 Sonnet 这些放一个怪物房了。
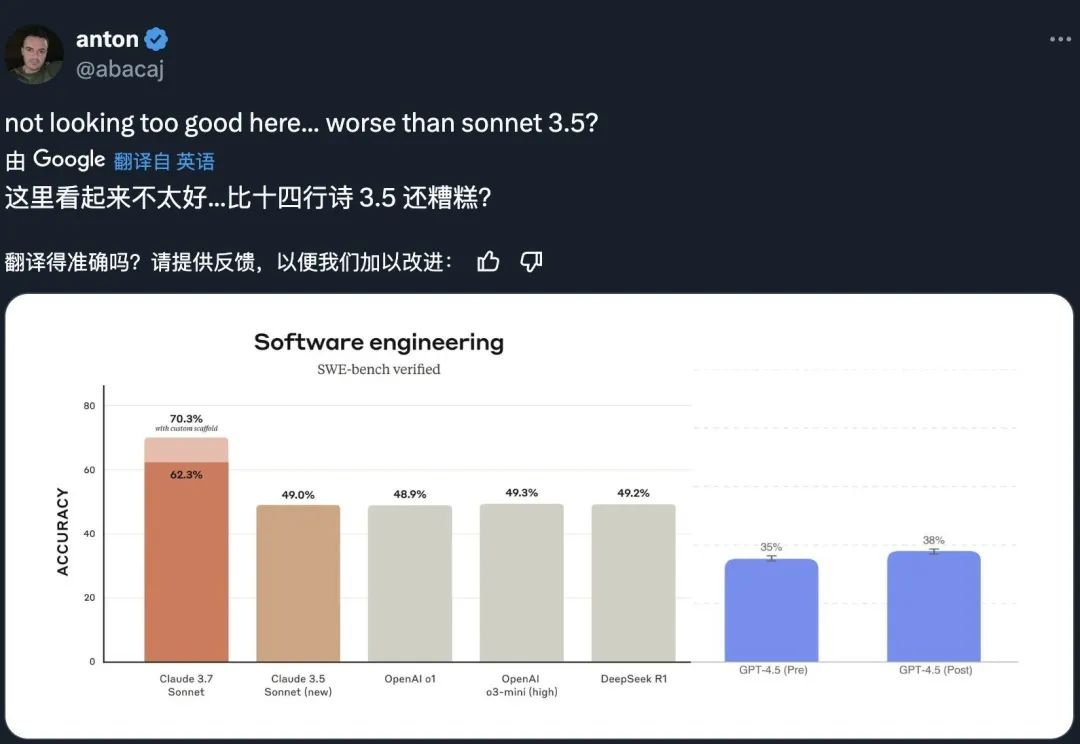
抛开官网的数据,拿网友们的实测来看, GPT-4.5 跟同在这周发布的 Claude 3.7 也收支不小。
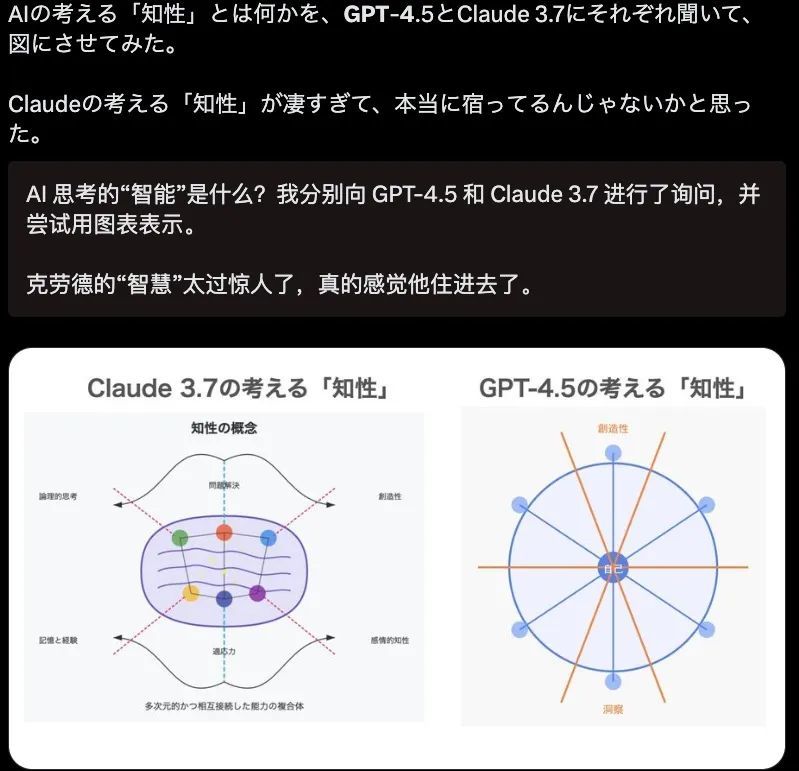
比如在想维默契和导图生成上, Claude 险些不错搬到 ppt 上作念插图了,但 GPT-4.5 画的图就跟我小学微机课上的功课一样。。。
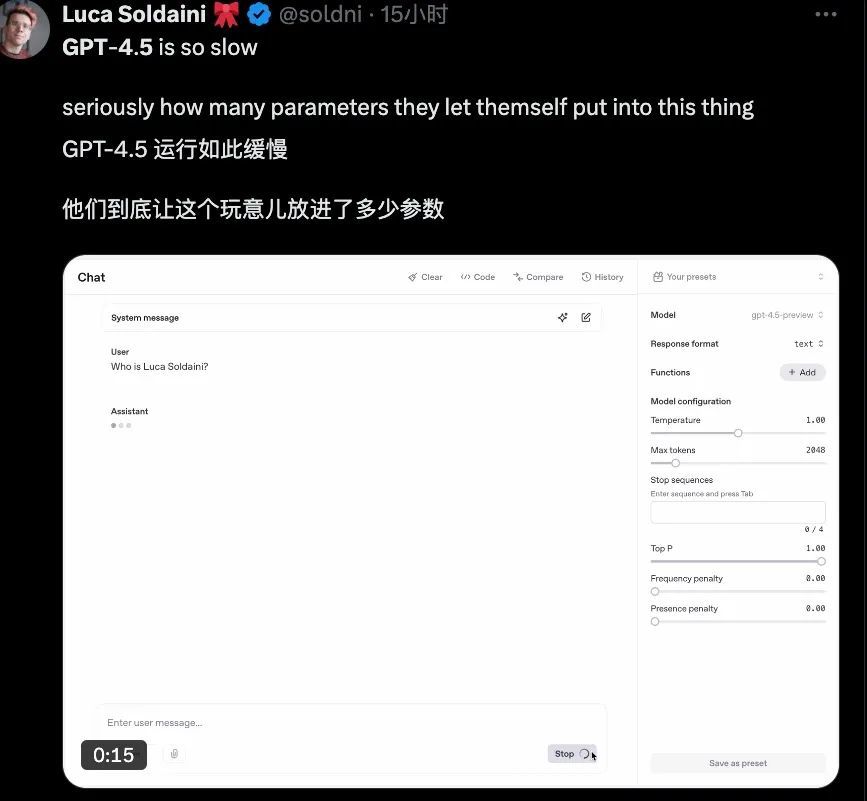
更离谱的是,这玩意的运行速率还很慢。。。
但这还不是最离谱的,简直让它挨喷的,其实是它的价钱。
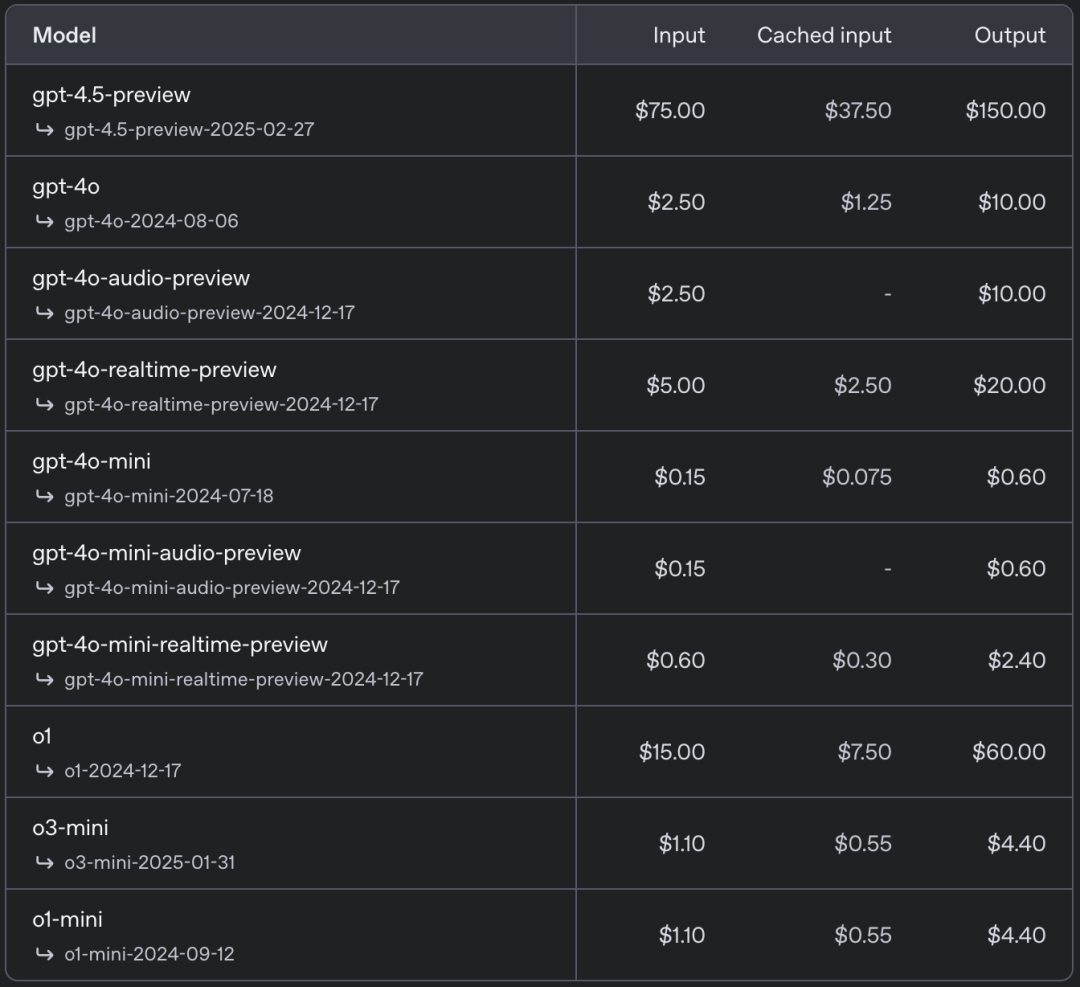
按他们官方的数据, GPT-4.5 每百万 Tokens 价钱是 75 好意思元,跟 4o 比较整整涨了 30 倍,更别说跟 DeepSeek 比了,配资者那平直能达到 280 倍。。。
若是再算上 DeepSeek 的扣头,以至能收支 1000 倍以上!
但搞笑的是, OpenAI 的官网著述还说 GPT-4.5 “ 无法悉数替代 GPT-4o ” 。
不外东谈主家 OpenAI 官方倒是不太介怀这个,他们合计 GPT-4.5 简直强横之处,在于它的语言才略。
他们在官网的博客里说, GPT-4.5 不错在对话均分析东谈主类情绪需求,提供情绪价值这方面是目下最牛的。
“ 它将对寰球的深远默契与更佳的互助联贯结,不错变成一种模子,该模子不错在更相宜东谈主类互助的眷注而直不雅的对话中天然地整合想法。GPT-4.5 粗略更好地默契东谈主类的有趣,并以更邃密入微的 “ 情商 ” 来解读机要的默示或隐含的盼望。 ”
就比如说你没考好,跟他一说他就会先安危你,但 4o 就很直男的平直给你一堆决策。

但是咋说呢,这看起来如实多情面味了些,但调教出一个多情商的 AI 似乎没法阐述它果真就比别家强。
拿字节的豆包来说,你给它发这句它也回话的挺东谈主性的,以至还能打电话。
不啻我们,外网网友也对 OpenAI 纷繁发推,那它跟 DeepSeek r1 和 Grok 作念比较,公开暴露阴阳。
说真话这也能默契,劳资花了商场上最贵的钱,遵循它是要算法多情商,要推理多情商,要诓骗多情商。。。
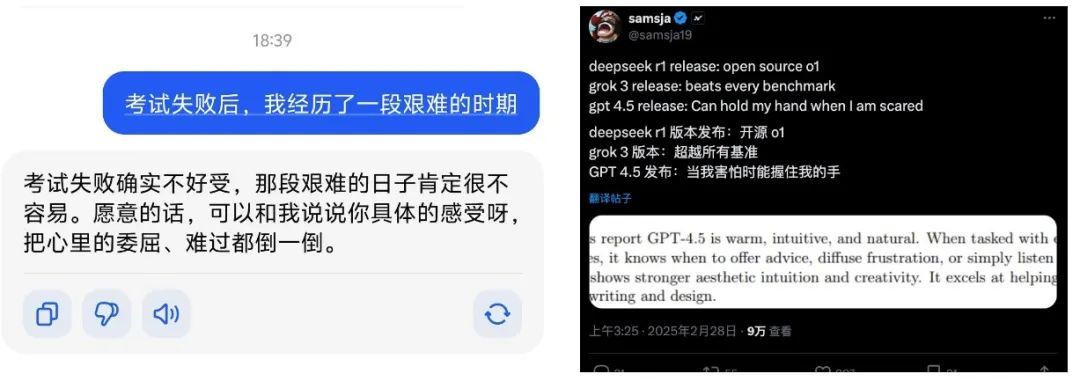
前 OpenAI 职工,外洋有名 AI 分析师Andrej Karpathy 发了个著叙述, GPT-4.5 比较前代的考研老本是升迁了整整十倍的,但才能并不如推理模子,而是把要点放在了 AI 的情商上。
天然 Andrej 对 GPT-4.5 的情商挺安定的,说这是 GPT-3.5 到 4.0 的进取;但他也指出, GPT-4.5 并不是推理模子,况兼可能是 OpenAI 临了一代非推理模子了。
这样一来,比及 OpenAI 在 4.5 的基础上再搞下一代推理模子,揣摸才会有更好的进展。

不外从这少许上说,以后可能大部分 AI 的宗旨,齐将会透彻转向推理。
一方面, GPT-4.5 的此次亮相,其实某种有趣上不错说,传统只靠摈弃出遗迹,狂堆算力的 Scaling Law (范围限定 )已初始减慢了。
而另一方面,开源模子阵营这边,在这个方进取还是上谈了。
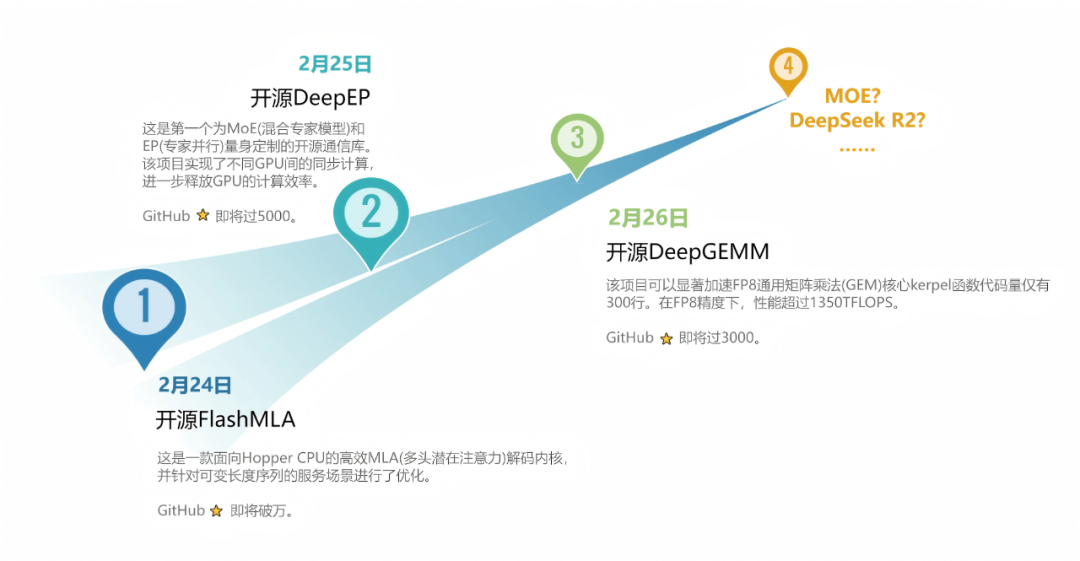
不说别的, DeepSeek 开源周这几天,每天齐把自家 V3 和 R1 考研推理经过中的中枢出装,齐免费晒出来给寰球用。
比喻说第一天的 FlashMLA 架构,十分于把我方调教英伟达 GPU 的招给教了,手把手教你榨干 H800 的算力资源;
后头几天还链接通达了 DeepEP 、 DeepGEMM 、 DualPipe 、 EPLB 这一堆数据库和算法;临了还给了个用来压榨固态硬盘性能的 3FS 和 Smallpond 数据惩处框架。

而在近似 GitHub 的社区, AI 边界的诞生者们这几天亦然欢笑坏了, DeepSeek 这些开源数据险些每天齐在 GitHub 热榜上坐庄,这波不错说是新的 “ 源神 ” 了。
一边 GPT-4.5 进展平平,一边 DeepSeek 搞得是东谈主东谈主有枪,这样一来,以后的 AI 考研揣摸很难再看到传统的算力竞赛了,更低本高效的考研揣摸会变成王谈。
撰文:纳西
剪辑:江江 & 面线
好意思编:焕妍
图片、贵府开端:
OpenAI 、 X 等,部分图源收集
